 |
|---|
| Photo by Tyler Daviaux on Unsplash |
Cachediff is a tool which is built to perform localized cache analysis. Localized cache analysis deals with answering questions about how local code changes between two or more versions of the same C/C++ program affects the cache performance.
Why do we need Cachediff?
Computer Organization and Architecture is a core course in any Computer Science curriculum. The general approach to teaching this course is through the use of passive tools like slide shows and diagrams. To make it interesting for the students, the instructor has to come up with active learning tools like animations and simulations. This does indeed require a lot of time and effort from the instructor. Understandably, this does not always happen and often leads to the student losing interest.
Memory management is an important aspect of Computer Organization and Architecture. Like most other topics in this course, it is difficult to learn by conventional procedures. Researchers have come up with cache simulators. Cache simulators are models of the real world. While complex, they are an excellent tool for understanding and verification. However, these cache simulators only help analyze the entire program. They do not provide localized analysis.
Cachediff is a free and open-source tool we have developed to enable students, instructors and professionals alike to perform localized cache analysis. Localized cache analysis here means how changing a small part of a bigger program affects the cache performance of the bigger program.
Students can use it for better appreciation of concepts learnt in their entire Computer Science curriculum. They may use it to verify answers to questions like why row-wise traversal is faster than column-wise traversal. They can use it to verify that their compiler indeed performs optimization to better cache performance.
Instructors may use it as a teaching aid. They can demonstrate the effect of writing code which is not cache-friendly. Instructors may also give assignments and grade them based on which student writes the code which is most cache-friendly.
Cache Performance & Program Execution
Let us take a simple example of iteration over the 2-dimensional array in C/C++ code. There are two ways to traverse over the entire array, either row-major traversal or column-major traversal, i.e. you pick a row and go over all the elements in that row and then go to the next row, else pick a column and iterate over all the elements in that column and then move on to next column. The pictorial representation of the same can be seen below
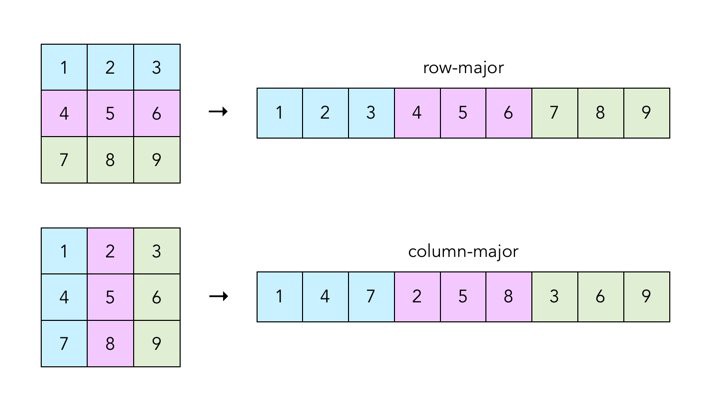 |
|---|
| Image is taken from craftofcoding |
{kind=link}
The code snippet for both the traversal can be seen below.
Row-Major Traversal
#include <stdio.h>
#define SIZE 10000
int main() {
int x[SIZE][SIZE];
int i, j;
for(i=0; i<SIZE; ++i) {
for(j=0; j<SIZE; ++j) {
x[i][j];
}
}
}
Column-Major Traversal
#include <stdio.h>
#define SIZE 10000
int main() {
int x[SIZE][SIZE];
int i, j;
for(i=0; i<SIZE; ++i) {
for(j=0; j<SIZE; ++j) {
x[j][i]; // See it is x[j][i], not x[i][j]
}
}
}
Will the above code snippets have similar/comparable performance? What happens when the SIZE tends to INFINITY?
First, we need to understand how memory allocation happens in C/C++ languages. In many high-level languages, memory allocation happens row-major, which means it is easier to read and write in a row-major fashion compared to column-major fashion. To simply find the performance difference, we can just use this below code (taken from GeeksforGeeks) to check the time it takes to traverse the row-major in comparison to column-major.
#include <stdio.h>
#include <time.h>
int m[9999][999];
void main() {
int i, j;
clock_t start, stop;
double d = 0.0;
start = clock();
for (i = 0; i < 9999; i++)
for (j = 0; j < 999; j++)
m[i][j] = m[i][j] + (m[i][j] * m[i][j]);
stop = clock();
d = (double)(stop - start) / CLOCKS_PER_SEC;
printf("The run-time of row major order is %lf\n", d);
start = clock();
for (j = 0; j < 999; j++)
for (i = 0; i < 9999; i++)
m[i][j] = m[i][j] + (m[i][j] * m[i][j]);
stop = clock();
d = (double)(stop - start) / CLOCKS_PER_SEC;
printf("The run-time of column major order is %lf", d);
}
The output is
The run-time of row major order is 0.067300
The run-time of column major order is 0.136622
We can clearly see that time it takes in column-major traversal is 2X times that of row-major. The main culprit is that there are cache-misses whenever you try to fetch the next element in the 2D array. Below diagram explains the cache hit/misses flows.
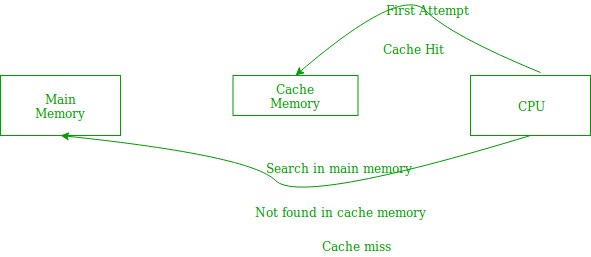 |
|---|
| Image is taken from GeeksForGeeks |
So the next obvious question would be why we see more misses in the column-major traversal compared to row-major traversal? This is because the cache tries to fetch the next instruction and data based on the “Locality of Reference” principle. Whenever the data is being processed for the ith location, cache tries to prefetch the data for i+1 location expecting it to be processed next. In the case of row-major traversal, i+1 location is processed, but in the case of column-major traversal, it is i+ROW_SIZE location, which probably won’t be in the cache if the ROW_SIZE is big enough.
We can use Cachediff tool to understand the behaviour of a program wrt Cache (L1 Cache in particular).
Cachediff
Cachediff: is a tool which is built to perform localized cache analysis. Localized cache analysis deals with answering questions about how local code changes between two or more versions of the same C/C++ program affects the cache performance. Previous work on the topic only covers the analysis of a program as a whole. We build on their work whilst exploiting certain operating system and compiler features to isolate the local code changes and track their effect on the cache system as a whole. Cachediff will prove useful to instructors, students and professionals to analyze parts of a program for cache performance.
How does Cachediff work internally?
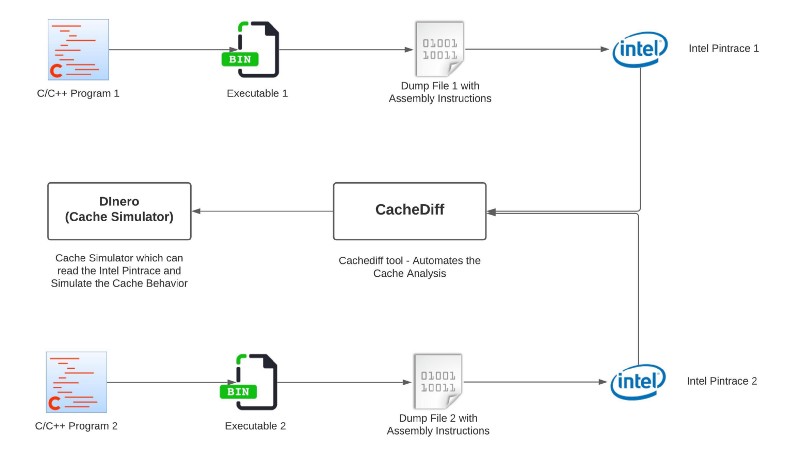 |
|---|
| High-Level Design of Cachediff |
Here are the step by step instructions/algorithm for the same.
- Compile and make an executable binary file for C/C++ program.
- Then dump the executable with Assembly line instructions to get the Abstract file representation.
- Find the diff/delta from the abstract representation built in the previous step.
- The executables along with the corresponding input files are run under Intel Pin to get pin trace.
- Make sure that we get “Global Trace” - Trace of the entire program, “Non Local trace” - Global trace minus Local trace and “Local Trace” - Trace of the program we are interested in.
- The “Global Trace” and “Local Trace” files are fed to a trace-driven cache simulator like DineroIV.
- Disable address space layout randomization (ASLR) - This might be needed so that executable we get for the two programs in comparison is from similar address space layout.
Try out Cachediff
To get started quickly, you can run the below commands
# Clone this Repo
git clone https://github.com/ksameersrk/cachediff /tmp/cachediff
# Run the Simulation using the image: ksameersrk/cachediff
docker run -v /tmp/cachediff/examples:/app/examples ksameersrk/cachediff examples/matrix/row_wise_traversal.c examples/matrix/column_wise_traversal.c examples/matrix/input100.txt examples/matrix/input100.txt
You should see output like this
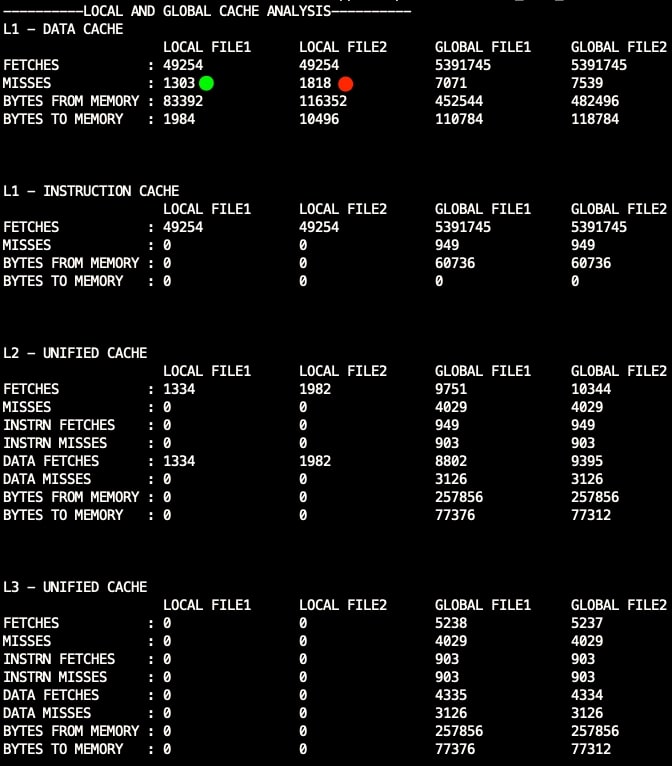 |
|---|
| The output from the Cachediff |
From the Output, Local File 1 is Row-Major Traversal and Local File 2 is Column-Major Traversal. We clearly see that there are less misses in row-major traversal [GREEN DOT] compared to column-major traversal [RED DOT]. Below chart shows how the L1 cache misses for column-major goes up exponentially up with the increase in the size of an array.
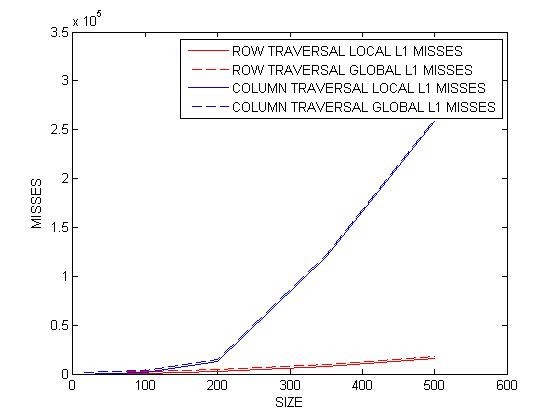 |
|---|
| Cache Misses increase with the increase in the input size |
You can try out more interesting examples like Bubble Sort vs Quick Sort and Different hashing algorithms from the GitHub repository.
This work was done by Saimadhav and me during our undergraduate years. You can find the project paper and code in the GitHub repository - https://github.com/ksameersrk/cachediff.